Como armazenar conhecimento com bancos de dados vetoriais?

Este artigo foi originalmente publicado no LinkedIn.

Como armazenar conhecimento com bancos de dados vetoriais?
Em um mundo inundado de dados não estruturados, como podemos armazenar não apenas informações, mas conhecimento?
Este artigo explora o conceito de bancos de dados vetoriais — uma tecnologia revolucionária que permite busca baseada em similaridade e compreensão semântica. Vamos entender o que são vetores, como são usados em Processamento de Linguagem Natural (PNL) e como embeddings permitem representações eficientes e contextualizadas da informação. Por fim, exploraremos aplicações do mundo real e por que os bancos de dados vetoriais estão se tornando essenciais em sistemas modernos de IA.
A Ascensão dos Dados Não Estruturados
Com o avanço do Big Data, bilhões de dispositivos conectados geram informações em tempo real na forma de texto, imagens, vídeos e mais. Esses formatos não estruturados não se encaixam bem em tabelas SQL tradicionais e exigem soluções de armazenamento mais sofisticadas. É aqui que os bancos de dados vetoriais surgem como uma abordagem inovadora, permitindo buscas baseadas em similaridade e armazenamento de conhecimento a partir de dados complexos.
Antes de mergulharmos em como os bancos de dados vetoriais funcionam, vamos primeiro recapitular os fundamentos dos bancos de dados.
O que é um Banco de Dados?
Um banco de dados é, simplificadamente, uma coleção organizada de informações que pode ser acessada, gerenciada e atualizada de forma eficiente. Ele atua como uma estrutura que armazena e organiza dados, facilitando consultas e manipulações por meio de software especializado.
Bancos de Dados Relacionais
Os bancos de dados relacionais são o tipo mais comumente usado. Eles armazenam dados em tabelas organizadas em linhas e colunas — onde cada linha representa um registro e cada coluna representa um campo ou atributo. Esse modelo é ideal para dados estruturados, como registros de clientes, transações bancárias ou inventários de produtos.
Um exemplo clássico é um banco de dados de clientes com colunas para nome, endereço, número de telefone e e-mail. Os bancos de dados relacionais permitem consultas rápidas e precisas, como “encontrar todos os clientes que fizeram uma compra nos últimos 30 dias”, usando uma linguagem conhecida como SQL (Structured Query Language).
Bancos de Dados Não Relacionais (NoSQL)
Ao contrário dos bancos de dados relacionais, os bancos de dados NoSQL são projetados para lidar com dados não estruturados ou semi-estruturados, oferecendo mais flexibilidade e escalabilidade. Eles armazenam informações em formatos diversos, como documentos JSON, pares chave-valor ou grafos. Isso os torna mais adequados para aplicações modernas, como plataformas de mídia social ou serviços de streaming.
Por exemplo, um banco de dados NoSQL orientado a documentos pode armazenar dados em formato JSON, permitindo estruturas de dados mais complexas e aninhadas — sem exigir um esquema rígido.
Entre as categorias de bancos de dados não relacionais, os bancos de dados vetoriais se destacam por sua capacidade de armazenar dados contextualizados — também conhecidos como conhecimento.
Bancos de Dados Vetoriais
Os bancos de dados vetoriais introduzem uma abordagem transformadora voltada para armazenar e recuperar dados como vetores — estruturas matemáticas que representam informações em múltiplas dimensões. Ao contrário dos bancos de dados tradicionais que dependem de correspondência exata, os bancos de dados vetoriais permitem buscas por similaridade, que são ideais para recuperar conteúdos como textos, imagens ou sons com base em suas características.
Isso nos leva a uma pergunta chave: o que é um vetor?
O que é um Vetor?
Um vetor é uma estrutura que armazena informações em várias dimensões. No caso de um vetor tridimensional, ele possui três coordenadas — (x, y, z) — que definem sua posição ou direção em um espaço 3D.
Um exemplo do mundo real é como as cores são representadas no modelo RGB (Vermelho, Verde, Azul). Uma cor é descrita por três valores, cada um representando a intensidade de vermelho, verde e azul. Por exemplo, o branco é [255, 255, 255], enquanto o preto é [0, 0, 0].
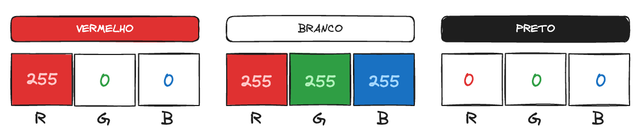
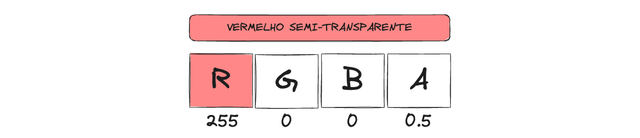
Esse conceito se estende para vetores 4D, como RGBA, onde o quarto componente “A” representa o alpha (transparência). Um vermelho semi-transparente poderia ser [255, 0, 0, 0.5].
Assim como as cores podem ser representadas por vetores em três ou quatro dimensões, os bancos de dados vetoriais usam vetores para organizar itens como palavras, imagens e sons em espaços multidimensionais, onde a distância entre vetores indica similaridade.
Representando Palavras com Vetores
Os vetores são amplamente utilizados para representar informações mais abstratas, como palavras. Em PNL, converter palavras em números é essencial para que as máquinas possam entendê-las e manipulá-las. Uma das técnicas mais simples é a One-Hot Encoding.
One-Hot Encoding
One-Hot Encoding é uma técnica onde cada palavra é transformada em um vetor de zeros e uns. Nesse vetor, cada posição corresponde a uma palavra específica no vocabulário, e apenas uma posição contém o valor "1" — todas as outras são definidas como "0".
Vamos considerar um conjunto de quatro palavras: cachorro, gato, pássaro e peixe. Usando One-Hot Encoding, essas palavras seriam representadas da seguinte forma:
- cachorro: [1, 0, 0, 0]
- gato: [0, 1, 0, 0]
- pássaro: [0, 0, 1, 0]
- peixe: [0, 0, 0, 1]
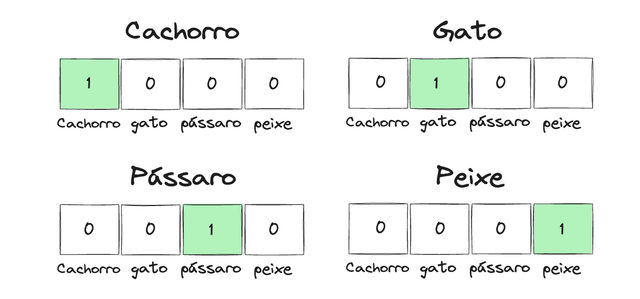
Cada vetor contém apenas um "1", indicando a palavra correspondente, enquanto os "0s" indicam que as outras palavras não estão presentes. Embora essa abordagem seja simples e fácil de implementar, ela apresenta algumas limitações — especialmente à medida que o vocabulário começa a crescer.
As Limitações da One-Hot Encoding
Embora simples, a One-Hot Encoding não captura as relações semânticas entre as palavras. No exemplo acima, "cachorro" e "gato" são tratados como completamente diferentes, mesmo que ambos sejam animais de estimação, tenham quatro patas, duas orelhas e uma cauda. Outra desvantagem aparece em cenários com grandes vocabulários — digamos, 10.000 palavras. Nesses casos, cada palavra seria representada por um vetor muito longo com um único "1" entre 10.000 posições, sem oferecer nenhuma indicação de como as palavras se relacionam entre si. Essa ineficiência e falta de informação semântica destacam a necessidade de técnicas mais avançadas para representar palavras como vetores de forma mais eficiente.
Representações Avançadas: Embeddings
Para superar essas limitações, foram introduzidos os embeddings — representações vetoriais densas e contínuas de palavras, onde palavras com significados semelhantes são colocadas próximas umas das outras no espaço vetorial. Ao contrário da One-Hot Encoding, os embeddings capturam o significado das palavras, posicionando termos relacionados — como “cachorro” e “gato” — próximos uns dos outros no espaço vetorial, uma vez que compartilham características comuns.
O Que São Embeddings?
Embeddings são uma forma de representar dados como vetores, onde itens semelhantes são posicionados próximos uns dos outros em um espaço multidimensional. Eles são amplamente utilizados em áreas como PNL para capturar relações entre palavras, imagens ou sons de forma mais eficaz do que métodos mais simples, como One-Hot Encoding.
Esses embeddings permitem que dados com características semelhantes se agrupem, o que torna a busca por similaridade e o agrupamento de informações relacionadas muito mais eficientes.
Uma Analogia Simples: Cores em um Espaço Vetorial 3D
Para facilitar a compreensão, vamos considerar um exemplo familiar: cores no modelo RGBA. Cada cor é representada por quatro valores — as intensidades de vermelho, verde e azul, além de um canal alfa que controla a transparência — colocando-a em um espaço quatro-dimensional (4D).
Como não podemos visualizar quatro dimensões diretamente, simplificamos plotando apenas os componentes RGB em um espaço 3D. O valor alfa ainda existe, mas não é representado visualmente nesta visão.
Por exemplo:
- Vermelho:
[255, 0, 0, 1] - Vermelho Claro:
[255, 0, 0, 0.5] - Verde:
[0, 255, 0, 1] - Azul:
[0, 0, 255, 1]
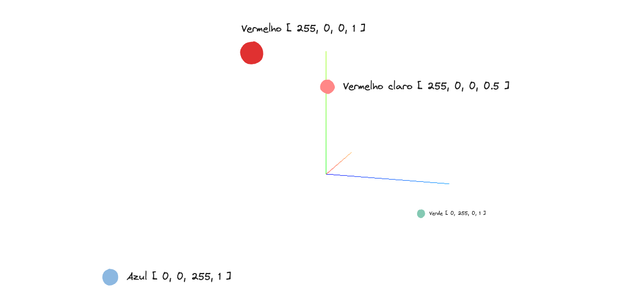
Quando plotamos essas cores em um espaço 3D usando apenas os componentes RGB, podemos ver claramente que Vermelho e Vermelho Claro aparecem próximos um do outro, enquanto Verde e Azul estão localizados mais distantes. Essa proximidade espacial reflete quão semelhantes as cores são — neste caso, devido à sua intensidade vermelha compartilhada.
Representando Palavras com Embeddings
Agora, vamos aplicar essa ideia a como representamos palavras. Em vez de usar três ou quatro dimensões como no modelo de cores RGB, as palavras são tipicamente representadas em espaços vetoriais com centenas ou até milhares de dimensões. Cada dimensão captura algum aspecto ou característica da palavra — como seu significado, contexto ou relações com outras palavras.
Por exemplo:
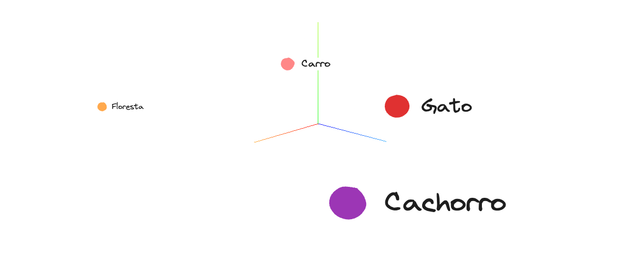
No exemplo acima, "cachorro" e "gato" aparecem próximos um do outro no espaço vetorial, porque ambos são animais de estimação e compartilham semelhanças contextuais. Por outro lado, "carro" e "floresta" estão posicionados mais distantes devido aos seus significados e padrões de uso muito diferentes.
Ilustrativo apenas — nenhum modelo real foi utilizado pra gerar esses vetores.
Esses espaços vetoriais de alta dimensão são gerados por modelos de embedding, que analisam grandes volumes de texto e aprendem a posicionar palavras com base nos contextos em que aparecem. Quanto mais próximas duas palavras estão no espaço, mais semanticamente semelhantes elas são.
Essa representação torna possível que as máquinas raciocinem sobre o significado — não apenas reconheçam correspondências exatas, mas entendam a relação. Essa é uma base fundamental para tarefas modernas de IA, como resposta a perguntas, tradução e busca semântica.
Explore uma Representação Real de Embedding
Se você gostaria de ver como os embeddings se parecem na prática, pode explorar uma visualização interativa ao vivo usando o TensorFlow Embedding Projector. Esta ferramenta permite que você navegue por espaços vetoriais de alta dimensão e observe como palavras, imagens ou outros pontos de dados são organizados com base em suas relações semânticas.
Você verá algo semelhante ao exemplo abaixo, onde cada palavra é plotada em um espaço com até 200 dimensões, reduzido visualmente para 2D ou 3D usando técnicas de redução de dimensionalidade como PCA ou t-SNE.
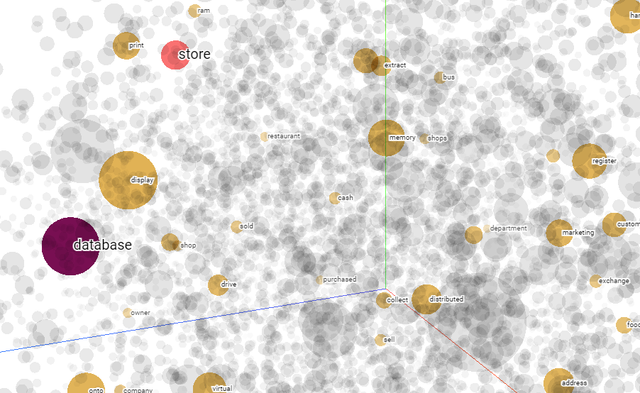
Nesta visualização, cada ponto representa uma palavra, e a proximidade entre eles reflete quão semelhantes seus significados são de acordo com o modelo de embedding. Por exemplo, a palavra “store” está cercada por palavras como “shop,” “market,” e “retail”, indicando que o modelo aprendeu sua semelhança contextual a partir de dados textuais em larga escala.
Esse tipo de espaço de embedding permite que as máquinas não apenas reconheçam termos individuais, mas também entendam as relações entre eles — uma capacidade poderosa para tarefas como busca semântica, onde o objetivo é encontrar informações relevantes com base no significado, em vez de correspondências exatas.
Como Funciona um Banco de Dados Vetorial?
Agora que cobrimos os conceitos básicos, podemos entender melhor como os bancos de dados vetoriais operam. Um banco de dados vetorial organiza dados na forma de vetores, que ocupam posições em espaço multidimensional. O principal objetivo é permitir a busca semântica — ou seja, encontrar itens semelhantes com base em sua proximidade vetorial, em vez de correspondências exatas como em bancos de dados tradicionais.
Por exemplo, imagine um banco de dados de imagens onde cada imagem é representada como um vetor que captura suas características visuais — como cor, forma e textura. Se você quiser encontrar imagens semelhantes a uma imagem específica de um gato, o banco de dados vetorial calculará a distância entre o vetor da imagem de consulta e os vetores de outras imagens armazenadas. Aqueles com a menor distância serão retornados como resultados, uma vez que compartilham características semelhantes.
Uma aplicação comum desse tipo é o reconhecimento facial, onde a semelhança entre o vetor de um rosto capturado e o de um rosto registrado pode indicar uma correspondência potencial.
Mas como exatamente a semelhança entre vetores é medida?
Distância Vetorial e Busca por Similaridade
Em um banco de dados vetorial, itens com características semelhantes são agrupados próximos uns dos outros em um espaço multidimensional. A "proximidade" — ou similaridade — entre os itens é determinada por métricas de distância específicas, como distância euclidiana ou similaridade por cosseno.
No caso de buscas por palavras, como em nosso exemplo anterior de embeddings, um banco de dados vetorial pode retornar palavras que estão semanticamente próximas da consulta. Por exemplo, se você pesquisar pela palavra "feline", o banco de dados pode retornar "cat," "tiger," ou "leopard", com base em quão próximos seus vetores estão no espaço semântico.
Esse tipo de correspondência baseada em vetores permite que os sistemas vão além de palavras-chave superficiais e encontrem resultados que estão significativamente relacionados, mesmo quando as palavras exatas não correspondem — uma grande vantagem em aplicações modernas de IA.
Aplicações de Bancos de Dados Vetoriais
Os bancos de dados vetoriais já estão sendo amplamente utilizados para resolver desafios relacionados a dados não estruturados em vários domínios. Aqui estão alguns exemplos práticos:
-
Busca de Imagens: Sistemas médicos e plataformas como o Google Imagens usam bancos de dados vetoriais para encontrar imagens visualmente semelhantes com base em características como cor, forma e textura — o que ajuda em diagnósticos e descoberta de conteúdo.
-
Recomendações de Produtos: No comércio eletrônico, os bancos de dados vetoriais sugerem produtos com base em buscas anteriores ou no histórico de compras do usuário, permitindo uma experiência de compra mais personalizada.
-
Reconhecimento Facial: Sistemas de segurança usam bancos de dados vetoriais para comparar imagens faciais, identificando correspondências com alta precisão — tornando a autenticação e vigilância mais eficazes.
-
RAG (Geração Aumentada por Recuperação): Essa técnica combina a recuperação de documentos de bancos de dados vetoriais com as capacidades de geração de respostas de grandes modelos de linguagem (LLMs). Isso permite que esses modelos se especializem em tópicos específicos sem exigir re-treinamento.
No meu trabalho de conclusão de curso, utilizei RAG para construir um chatbot focado em saúde mental. O sistema recupera informações relevantes e fornece respostas mais precisas e contextualizadas.
Conclusão
À medida que os dados não estruturados continuam a crescer exponencialmente, os bancos de dados vetoriais estão se tornando essenciais para recuperar informações de forma eficiente e significativa. Ao permitir a busca baseada em similaridade em vez de depender de correspondências exatas, eles abrem novas possibilidades para interagir com dados complexos de maneiras mais intuitivas e inteligentes.
Desde aplicações como busca de imagens, recomendações de produtos e reconhecimento facial, até o suporte a técnicas avançadas como RAG, os bancos de dados vetoriais estão prontos para desempenhar um papel fundamental no futuro da inteligência artificial. Eles ajudam a preencher a lacuna entre dados brutos e conhecimento acionável — impulsionando a inovação em diversos setores.
Em um mundo onde contexto e significado importam mais do que nunca, os bancos de dados vetoriais oferecem uma mudança de paradigma. Ao interpretar dados semânticamente, eles têm o potencial de revolucionar a forma como armazenamos, recuperamos e entendemos informações — conectando os sistemas digitais de hoje com as tecnologias orientadas ao conhecimento de amanhã.
Referências
Links
- What is Big Data? – Oracle
- What is a Database? – Oracle
- What is a Database? – AWS
- What is a Vector Database? – AWS
- What is a Vector Embedding? – Elastic
- Word Embedding: Making Computers Understand Word Meaning – Turing Talks
- Embeddings – Google Machine Learning Crash Course
- What is Retrieval-Augmented Generation (RAG)? – AWS