From Data to Knowledge: The Power of Vector Databases


From Data to Knowledge: The Power of Vector Databases
In a world flooded with unstructured data, how can we store not just information, but knowledge itself?
This article explores the rise of vector databases — a revolutionary technology that enables similarity-based search and semantic understanding. We'll break down what vectors are, how they're used in Natural Language Processing (NLP) and how embeddings allow for efficient, contextualized representations of information. Finally, we’ll explore real-world applications and why vector databases are becoming essential in modern AI systems.
The Rise of Unstructured Data
With the advance of Big Data, billions of connected devices generate real-time information in the form of text, images, videos, and more. These unstructured formats don't fit well into traditional SQL tables and demand more sophisticated storage solutions. This is where vector databases emerge as a game-changing approach, enabling similarity-based searches and unlocking knowledge from complex data.
Before we dive into how vector databases work, let’s first recapitulate the fundamentals of databases.
What Is a Database?
A database is, simply put, an organized collection of information that can be efficiently accessed, managed and updated. It acts as a structure that stores and organizes data, making it easy to query and manipulate using specialized software.
Relational Databases
Relational databases are the most commonly used type. They store data in tables organized into rows and columns — where each row represents a record and each column represents a field or attribute. This model is ideal for structured data such as customer records, bank transactions, or product inventories.
A classic example is a customer database with columns for name, address, phone number and email. Relational databases enable fast and precise queries like “find all customers who made a purchase in the last 30 days,” using a language known as SQL (Structured Query Language).
Non-Relational Databases (NoSQL)
Unlike relational databases, NoSQL databases are designed to handle unstructured or semi-structured data, offering more flexibility and scalability. They store information in diverse formats such as JSON documents, key-value pairs or graphs. This makes them better suited for modern applications like social-media platforms or streaming services.
For instance, a document-oriented NoSQL database might store data in JSON format, allowing for more complex and nested data structures — without requiring a rigid schema.
Among the categories of non-relational databases, vector databases stand out for their ability to store contextualized data — also known as knowledge.
Vector Databases
Vector databases introduce a transformative approach tailored to store and retrieve data as vectors — mathematical structures that represent information in multiple dimensions. Unlike traditional databases that rely on exact matching, vector databases enable similarity searches, which are ideal for retrieving content like texts, images or sounds based on their characteristics.
This brings us to a key question: what is a vector?
What Is a Vector?
A vector is a structure that stores information across multiple dimensions. In the case of a three-dimensional vector, it has three coordinates — (x, y, z) — that define its position or direction in a 3-D space.
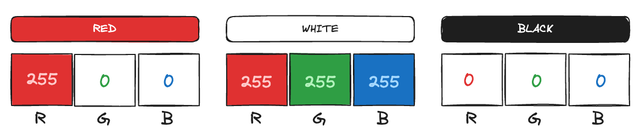
A real-world example is how colors are represented in the RGB model (Red, Green, Blue). A color is described by three values, each representing the intensity of red, green and blue. For instance, white is [255, 255, 255], while black is [0, 0, 0].
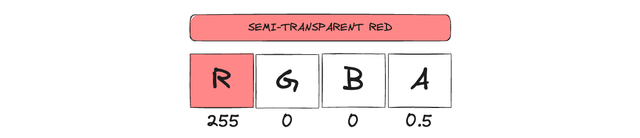
This concept extends to 4-D vectors, such as RGBA, where the fourth component “A” stands for alpha (transparência). A semi-transparent red poderia ser [255, 0, 0, 0.5].
Just as colors can be represented by vectors in three or four dimensions, vector databases use vectors to organize items such as words, images and sounds in multidimensional spaces, where the distance between vectors indicates similarity.
Representing Words with Vectors
Vectors are widely used to represent more abstract information, such as words. In NLP, converting words into numbers is essential for machines to understand and manipulate them. One of the simplest techniques is One-Hot Encoding.
One-Hot Encoding
One-Hot Encoding is a technique in which each word is transformed into a vector of zeros and ones. In this vector, each position corresponds to a specific word in the vocabulary, and only one position holds the value "1" — all the others are set to "0".
Let’s consider a set of four words: dog, cat, bird, and fish. Using One-Hot Encoding, these words would be represented as follows:
- dog: [1, 0, 0, 0]
- cat: [0, 1, 0, 0]
- bird: [0, 0, 1, 0]
- fish: [0, 0, 0, 1]
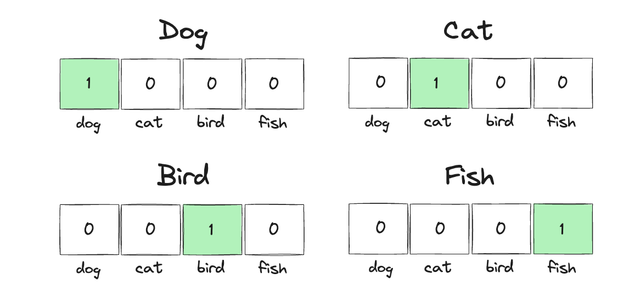
Each vector contains only one "1", indicating the corresponding word, while the "0s" indicate that the other words are not present. Although this approach is simple and easy to implement, it comes with some limitations — especially as the vocabulary begins to grow.
The Limitations of One-Hot Encoding
Although simple, One-Hot Encoding doesn't capture semantic relationships between words. In the example above, "dog" and "cat" are treated as completely different, even though both are household pets, have four legs, two ears, and a tail. Another drawback appears in scenarios with large vocabularies — say, 10,000 words. In such cases, each word would be represented by a very long vector with a single "1" among 10,000 positions, offering no indication of how the words relate to one another. This inefficiency and lack of semantic information highlight the need for more advanced techniques to represent words as vectors in a meaningful way.
Advanced Representations: Embeddings
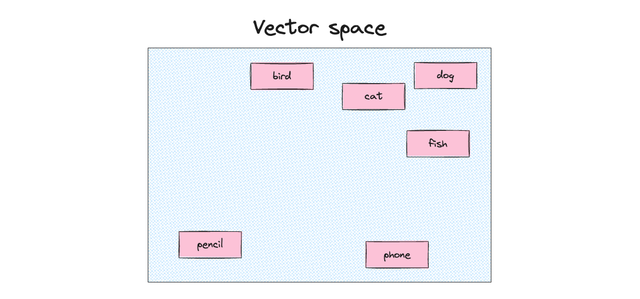
To overcome these limitations, embeddings were introduced — dense and continuous vector representations of words, where words with similar meanings are placed close to each other in the vector space. Unlike One-Hot Encoding, embeddings capture the meaning of words, positioning related terms — like “dog” and “cat” — near each other in the vector space, since they share common features.
What Are Embeddings?
Embeddings are a way to represent data as vectors, where similar items are positioned close to one another in a multidimensional space. They are widely used in areas like NLP to capture relationships between words, images, or sounds more effectively than simpler methods like One-Hot Encoding.
These embeddings allow data with similar characteristics to cluster together, which makes similarity search and grouping of related information much more efficient.
A Simple Analogy: Colors in a 3-D Vector Space
To make this easier to understand, let’s consider a familiar example: colors in the RGBA model. Each color is represented by four values — the intensities of red, green, and blue, plus an alpha channel that controls transparency — placing it in a four-dimensional (4D) space.
Since we can’t visualize four dimensions directly, we simplify by plotting just the RGB components in a 3D space. The alpha value still exists, but isn't represented visually in this view.
For example:
- Red:
[255, 0, 0, 1] - Light Red:
[255, 0, 0, 0.5] - Green:
[0, 255, 0, 1] - Blue:
[0, 0, 255, 1]
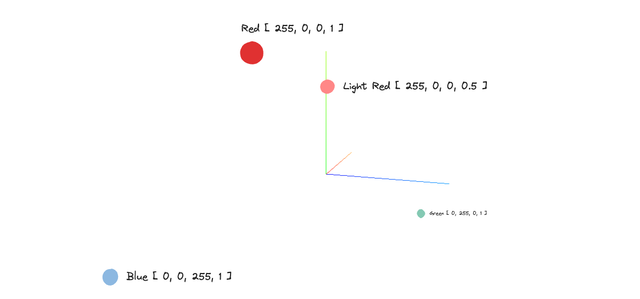
When we plot these colors in a 3D space using only the RGB components, we can clearly see that Red and Light Red appear close to each other, while Green and Blue are located farther away. This spatial proximity reflects how similar the colors are — in this case, due to their shared red intensity.
Representing Words with Embeddings
Now, let’s apply this idea to how we represent words. Instead of using three or four dimensions like in the RGB color model, words are typically represented in vector spaces with hundreds or even thousands of dimensions. Each dimension captures some aspect or feature of the word — such as its meaning, context, or relationships with other words.
For example:
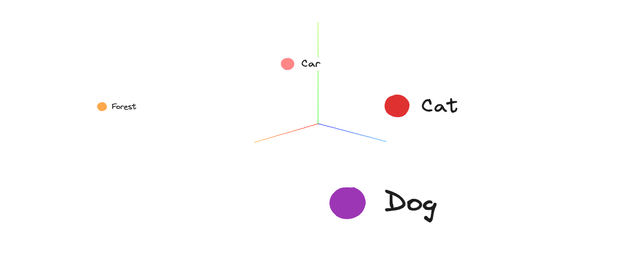
In the example above, "dog" and "cat" appear close to each other in the vector space, because both are pets and share contextual similarities. On the other hand, "car" and "forest" are positioned farther away due to their very different meanings and usage patterns.
Illustrative only — no actual model was used to generate this plot.
These high-dimensional vector spaces are generated by embedding models, which analyze large volumes of text and learn to position words based on the contexts in which they appear. The closer two words are in the space, the more semantically similar they are likely to be.
This representation makes it possible for machines to reason about meaning — not just recognize exact matches, but understand relatedness. That’s a key foundation for modern AI tasks like question answering, translation, and semantic search.
Explore a Real Embedding Representation
If you’d like to see what embeddings look like in practice, you can explore a live, interactive visualization using the TensorFlow Embedding Projector. This tool allows you to navigate through high-dimensional vector spaces and observe how words, images, or other data points are organized based on their semantic relationships.
You'll see something similar to the example below, where each word is plotted in a space with up to 200 dimensions, reduced visually to 2D or 3D using dimensionality reduction techniques like PCA ou t-SNE.
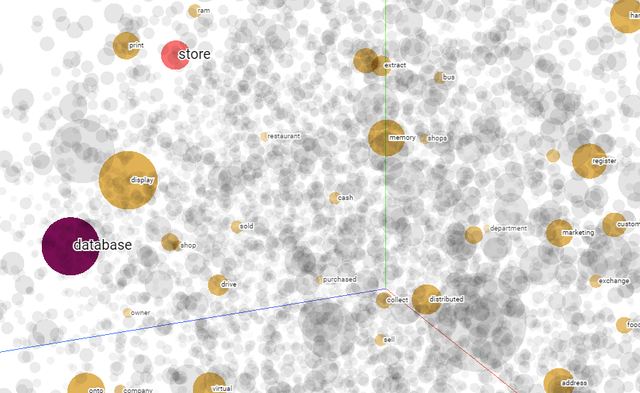
In this visualization, each dot represents a word, and the proximity between them reflects how similar their meanings are according to the embedding model. For example, the word “store” is surrounded by words like “shop,” “market,” and “retail”, indicating that the model has learned their contextual similarity from large-scale text data.
This type of embedding space enables machines not only to recognize individual terms, but also to understand relationships between them — a powerful capability for tasks like semantic search, where the goal is to find relevant information based on meaning rather than exact matches.
How Does a Vector Database Work?
Now that we’ve covered the basic concepts, we can better understand how vector databases operate. A vector database organizes data in the form of vectors, which occupy positions in multidimensional space. The main goal is to enable semantic search — that is, finding similar items based on their vector proximity, rather than exact matches like in traditional databases.
For example, imagine a database of images where each image is represented as a vector that captures its visual characteristics — such as color, shape, and texture. If you want to find images similar to a specific picture of a cat, the vector database will compute the distance between the query image's vector and the vectors of other stored images. Those with the shortest distance will be returned as results, since they share similar characteristics.
A common real-world application of this is facial recognition, where the similarity between the vector of a captured face and that of a registered face can indicate a potential match.
But how exactly is similarity between vectors measured?
Vector Distance and Similarity Search
In a vector database, items with similar features are clustered close to each other in a multidimensional space. The "closeness" — or similarity — between items is determined by specific distance metrics, such as Euclidean distance or cosine similarity.
In the case of word searches, like in our earlier embeddings example, a vector database can return words that are semantically close to the query. For instance, if you search for the word "feline", the database might return "cat," "tiger," or "leopard", based on how near their vectors are in the semantic space.
This kind of vector-based matching allows systems to go beyond surface-level keywords and find results that are meaningfully related, even when the exact words don’t match — a major advantage in modern AI applications.
Applications of Vector Databases
Vector databases are already being widely used to solve challenges related to unstructured data across various domains. Here are some practical examples:
-
Image Search: Medical systems and platforms like Google Images use vector databases to find visually similar images based on features like color, shape, and texture — which helps with diagnoses and content discovery.
-
Product Recommendations: In e-commerce, vector databases suggest products based on past searches or user purchase history, enabling a more personalized shopping experience.
-
Facial Recognition: Security systems use vector databases to compare facial images, identifying matches with high precision — making authentication and surveillance more effective.
-
RAG (Retrieval-Augmented Generation): This technique combines document retrieval from vector databases with the response generation capabilities of large language models (LLMs). It allows these models to specialize in specific topics without requiring retraining.
In my undergraduate thesis, I used RAG to build a chatbot focused on mental health. The system retrieves relevant information and provides more accurate and contextualized responses.
Conclusion
As unstructured data continues to grow exponentially, vector databases are becoming essential for retrieving information efficiently and meaningfully. By enabling similarity-based search rather than relying on exact matches, they open up new possibilities for interacting with complex data in more intuitive and intelligent ways.
From applications like image search, product recommendations, and facial recognition, to powering advanced techniques such as RAG, vector databases are poised to play a foundational role in the future of artificial intelligence. They help bridge the gap between raw data and actionable knowledge — fueling innovation across industries.
In a world where context and meaning matter more than ever, vector databases offer a paradigm shift. By interpreting data semantically, they have the potential to revolutionize the way we store, retrieve, and understand information — connecting today’s digital systems with the knowledge-driven technologies of tomorrow.
References
Links
- What is Big Data? – Oracle
- What is a Database? – Oracle
- What is a Database? – AWS
- What is a Vector Database? – AWS
- What is a Vector Embedding? – Elastic
- Word Embedding: Making Computers Understand Word Meaning – Turing Talks
- Embeddings – Google Machine Learning Crash Course
- What is Retrieval-Augmented Generation (RAG)? – AWS